微软等开源评估ChatGPT、Phi、Llma等,统一测试平台:一站式评估ChatGPT、Phi、Llma等开源工具的最佳测试平台
Prompt Bench支持目前主流的开源、闭源大语言模型,例如。ChatGPT、GPT-4、Phi、Llma1/2、Gemini、Baichuan、Yi 等。
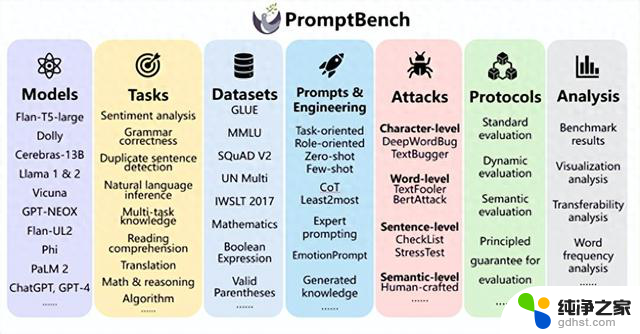
PromptBench内置了丰富的评估工具,包括提示构建、提示工程、数据集和模型、对抗性提示攻击、性能评测等。用户可以根据实际开发情况灵活配置,非常简单高效。
开源地址:https://github.com/microsoft/promptbench
论文地址:https://arxiv.org/abs/2312.07910
对大型语言模型进行评估、分析是理解其真实输出、减少潜在风险的重要开发环节。
研究人员表示,目前多数大型语言模型对文本提示非常敏感,容易受到对抗性提示攻击,同时易受到数据污染的影响,这给安全和隐私带来了巨大挑战。
虽然有很多类似lm-eval-harness的评估框架,但其评估模块和功能较少,无法满足飞速发展的大语言模型领域。
所以,微软等研究人员希望开发一个统一的评估平台,帮助开发者提升测试效率,同时减少大模型的非法内容输出。
PromptBench简单介绍
PromptBench可以从多个维度对大语言模型进行评估,涵盖多个任务、评估协议、对抗性提示攻击和提示工程技术、数据集等。
评估协议是PromptBench的核心模块之一,主要定义了评估大语言模型性能的方法和流程。
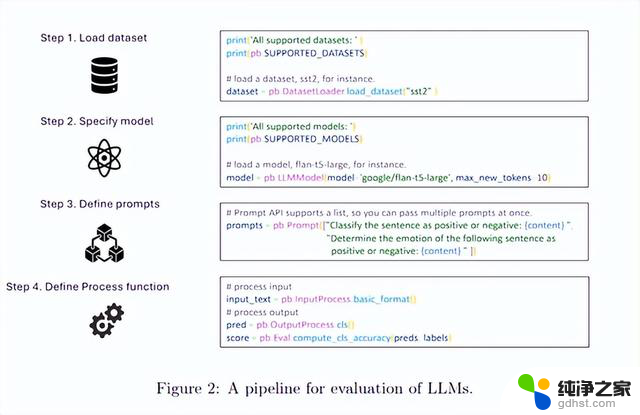
PromptBench支持多种评估协议,包括静态评估和动态评估。静态评估是,通过提供预定义的提示来测试大语言模型的性能;
动态评估,则允许在交互过程中动态生成和修改提示。这种灵活性使研究人员能够更全面地评估大语言模型的能力和鲁棒性。
对抗性提示攻击,是评估大语言模型安全性的重要方法之一。PromptBench提供了多种对抗性提示攻击的测试方法,包括,字符级修改、词级替换、句级添加和语义级改写等攻击。有效模拟了提示使用中可能遇到的各类偏差情况,检验了模型的攻击鲁棒性。
数据集是评估大语言模型性能的关键部分。PromptBench提供了20多个公开的评估数据集,涵盖了文本分类、语法纠错、句子相似度判定、自然语言推理、多任务问答、阅读理解、翻译、数学推理、逻辑推理等。可以充分测试大语言模型在不同场景下的表现和能力。
支持哪些大语言模型
PromptBench支持目前市面上主流的开源、闭源大语言模型,包括Flan-T5-large、Dolly系列、Cerebras-13B 、Llama系列、Vicuna 、GPT-NEOX;
Flan-UL2、Phi 、PaLM 2、ChatGPT、GPT-4、Gemini、Mistral、Mixtral、Baichuan、Yi等。
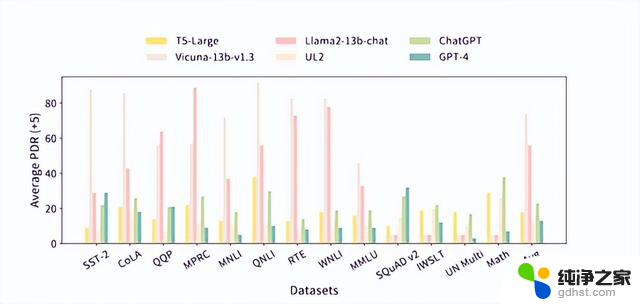
研究人员表示,未来会持续更新对大语言模型的支持,将打造成一个涵盖模型最多、评估功能最全的统一测试平台。
本文素材来源PromptBench论文,如有侵权请联系删除
END
微软等开源评估ChatGPT、Phi、Llma等,统一测试平台:一站式评估ChatGPT、Phi、Llma等开源工具的最佳测试平台相关教程
-
 微软发布.NET8开源开发平台,性能提升20%,引入PGO和AVX-512支持
微软发布.NET8开源开发平台,性能提升20%,引入PGO和AVX-512支持2023-11-15
-
 如何全面评估显卡配置,选择适合自己的显卡?显卡性能评测指南
如何全面评估显卡配置,选择适合自己的显卡?显卡性能评测指南2024-10-12
-
 微软退出物联网应用平台,物联网平台未来前景如何?
微软退出物联网应用平台,物联网平台未来前景如何?2024-03-09
-
 微软正在为 Word 中的新文档测试新的 Copilot UI,提升办公效率
微软正在为 Word 中的新文档测试新的 Copilot UI,提升办公效率2024-11-06
- Win10版微软Edge浏览器探索新功能:一站式工具栏大揭秘
- AMDRyzenAI9HX370性能实测:AI性能大跃进,性能测试报告全面解析
- 显卡-GPU性能排名及评测:哪款显卡性价比最高?
- 阿凡达:潘多拉边境索泰显卡评测:惊艳绝伦的画面体验
- 等等党下山的最好时机,2024年末大促显卡推荐:如何选择性价比最高的显卡?
- Windows 11新设计的开始菜单应用程序网格功能测试报告
- CPU和GPU有什么区别,玩游戏哪个更重要?如何选择最佳配置?
- 如何激活Windows系统,轻松解决电脑激活问题,快速激活Windows系统步骤指南
- 10-3:WIN7开机进入系统和简介如何操作?详细解析步骤
- 英伟达要去日本造GPU?为何选择日本?
- 国产GPU公司为何扎堆冲刺IPO?要钱、借红利、打知名度
- 英伟达PC端Nvidia应用正式上线,取代GeForce Experience,提升游戏性能和体验
微软资讯推荐
- 1 如何激活Windows系统,轻松解决电脑激活问题,快速激活Windows系统步骤指南
- 2 10-3:WIN7开机进入系统和简介如何操作?详细解析步骤
- 3 英伟达要去日本造GPU?为何选择日本?
- 4 国产GPU公司为何扎堆冲刺IPO?要钱、借红利、打知名度
- 5 英伟达PC端Nvidia应用正式上线,取代GeForce Experience,提升游戏性能和体验
- 6 等等党下山的最好时机,2024年末大促显卡推荐:如何选择性价比最高的显卡?
- 7 详细步骤教你如何在Win7系统中连接网络,快速实现网络连接
- 8 AMD Zen 6处理器Medusa系列发布:桌面、移动端全覆盖
- 9 微软不再喜欢您下载Windows 10 即使是从官方来源,这是为什么?
- 10 微软发布最新Win11 27744 Canary预览版,首次引入Prism技术模拟任意x64应用
win10系统推荐